
The traditional approach to IT operations is primarily ticket-based. When a tool or a user observes a problem, a ticket is raised, and the support and operations teams work towards resolving the ticket. This approach works, but there are two problems:
- The approach is inherently reactive. It waits for issues to occur and then fixes them.
- The primary focus is on improving the Service Level Agreement (SLA) compliance for ticket resolution, and not on improving the stability of the system or the end-user experience.
With ticketless operations, we are driving a paradigm shift from SLAs to Experience Level Agreements (XLAs). We delved into the question, can we use the information present in logs, time-series, events, incidents and change requests, to improve system stability and end-user experience?
We found our answer in two principles:
- Eliminate Over Automate: We ask the question, instead of automating the resolution of an issue, can we eliminate it in the first place? Can we use AI/ML and augmented intelligence to find recurring issues that have diagnosable causes and fixes?
- Prevent Over React: Not all issues can be eliminated. We might not always find a diagnosable cause, or we might not find a fix for them. But if we cannot eliminate an issue, can we try to predict it ahead of time? Can we use machine learning advancements to find predictability in recurring issues?
With these two principles, we have developed the first version of insights for ticketless operations. Note that, by ‘ticketless operations’, we do not mean that there will not be any tickets or any IT Service Management (ITSM). They will still exist, but they will exist more as a system of records and not as a system of engagement.

Eliminate Over Automate
Let us dive deeper into the first principle, ‘Eliminate Over Automate’. Objective here is:
‘Mine the history of events, metrics, logs and changes, to look for recurring issues with diagnosable causes and fixes.’
We realized this principle in practice in four steps:
- It is very important to not only rely on incidents, but instead, look for anomalies in other sources such as metrics, events and logs. We have developed a complex event processing engine to detect a wide variety of anomalies. We detect anomalies that occur at a point-in-time. We also detect anomalies that last over a span of time. Moreover, we detect multi-variate anomalies by analyzing multiple metrics together.
- We analyze these anomalies to create problem signatures using spatio-temporal correlations. Traditionally, most tools stop analysis at this point. We take it two steps ahead.
- We localize the root cause of this problem signature. This step involves Bayesian reasoning and sequence mining to analyze the chain of actions that lead to an issue. This helps narrow down the root cause.
- After a cause is localized, we take the analysis one step ahead to recommend fixes. We take the route of augmented intelligence to infer fixes. We bring in human experts to take guidance. The solution keeps learning from human recommendations. After an expert provides a recommendation, next time when the same or a similar problem occurs, the solution suggests fixes that were recommended by the experts in the past. With use, this human-in-the-loop engine gets richer and richer in its knowledge base to recommend fixes.

Prevent instead of React
Let us dive deeper into the second principle, ‘Prevent over React’. Not all incidents can be eliminated. Hence, we explore for the possibility, if we cannot eliminate an incident, can we predict it? Objective here is:
‘Mine the history of events, metrics, logs and changes, to look for recurring issues that show some sort of predictability.’
To realize this principle in practice, we focus on different ways of finding predicable issues:
- We first look for the most obvious cases where events show temporal patterns. For example, an application backup fails every Monday morning.
- Not all predictable incidents may show temporal patterns. Some incidents may not have strong temporal occurrences, but they show a clear pre-condition. For example, when the disk is more than 80% full, the backup fails, or when the queue length is more than 45, the requests get stuck. We mine such pre-conditions using association rule mining.
- Lastly, there are some cases where predictability exists, but it is not very well defined in the form of patterns or associations. For such cases, we use neural-networks-based predictions. We train neural networks on historical data to predict future events.
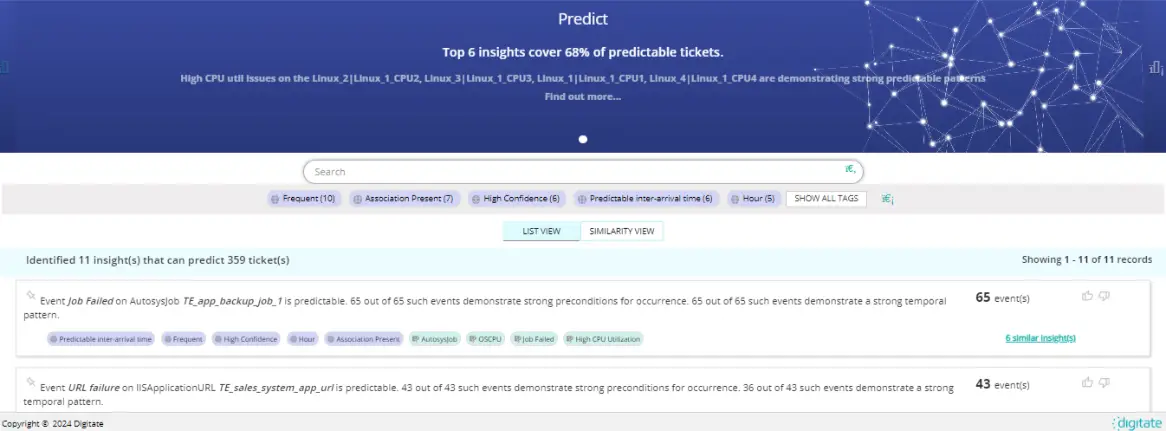
Key highlights
The following are the key highlights of our ticketless solution that uniquely stand out in this solution to derive insights from:
- The foundation of this solution is built on a complex event processing engine that can detect a wide variety of anomalies.
- It mines detailed problem signatures that not only mine correlations, but also use Bayesian reasoning and sequence mining to derive a possible causality.
- It contains a wide range of algorithms to infer predictability including both white-box and black-box algorithms.
- This solution is designed to become increasingly intelligent as people use it. Its feedback-based-learning mechanism continuously evolves with time.
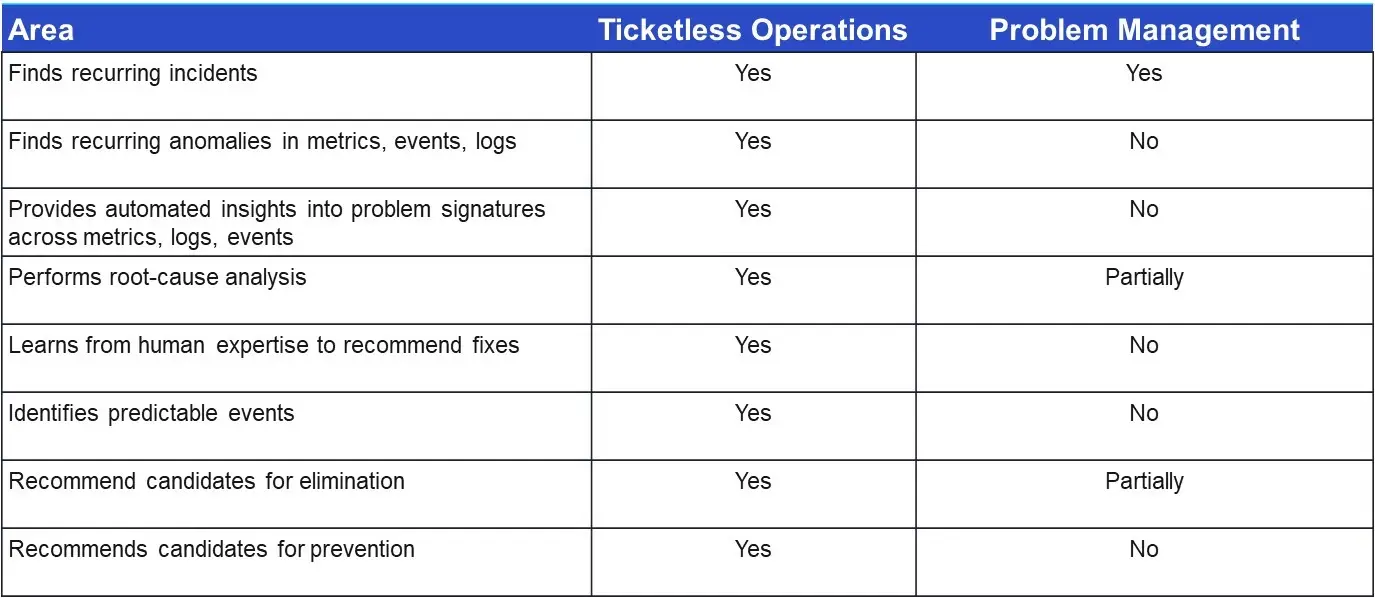
Comparing Ticketless with existing solutions for Problem Management
Most traditional problem management solutions revolve around analyzing past tickets to find long-term fixes. The following is a high-level comparison sheet with traditional problem management solutions available in the market.
Conclusion
The world of enterprise-IT is changing. Increasing focus on observability, advances in AI/ML algorithms, and easy access to compute infrastructure are opening new opportunities. It is time to leverage these advances and reimagine IT operations to change the focus from the SLAs of ticket resolutions to the Experience-Level Agreements of stability of applications and the experience of the end-users.
