
Telemetry Data Lifecycle
So far, we have learned that Telemetry data (MELT) is at the core of everything when we talk about Observability. Let’s take a quick view of what are the different stages of Telemetry data lifecycle, right from its creation to usage for an observable system.

- Generate: It all begins with the generation of Telemetry data, which provides insights into the system’s health and performance. This is achieved through a process known as ‘Instrumentation’. OpenTelemetry offers two ways to instrument your code:
- Code-based instrumentation
- OpenTelemetry code instrumentation supports many popular programming languages (Java, Java Script, C++, C#, .NET, Go, PHP, Python, Ruby, to name a few)
- Suitable where code access is available
- Provides better observability and developer experience
- Enables coherent traces, logs, and metrics
- Zero-code instrumentation
- Good for getting started or when you do not have access to the application code
- OpenTelemetry instrumentation works on the libraries used by your application code and/or the environment code runs in, to generate telemetry data
- Instrumentation library added as a dependency
- Less control over tracing and metrics

Both instrumentation methods can be used simultaneously.
- Emit: Once telemetry data is generated, the next step is to have it sent to the end-point service OR to a Collector using OpenTelemetry Protocol (OTLP).
- OTel Collector: OpenTelemetry collector offers vendor-agnostic implementation of how to receive, process, and export telemetry data. It eliminates the need to run, operate, and maintain multiple agents/collectors. It is particularly useful with complex, large scale environments with multiple data sources and backends for Telemetry data.
- Collect: Receivers collect telemetry data from one or more sources. It can be PULL/PUSH based data collection
- Process: Data collected is transformed, as needed, as per the rules or settings defined for each processor and collected data type. This includes data filtering, dropping, renaming among many other operations
- Export: Exporters send data to one or more backends or destinations. These can be PULL/PUSH based and may support multiple data sources
Using Collector in production environment is best practice.
- Observability backend and frontend: These do not need to be two different systems, and they fall entirely outside the purview of OpenTelemetry. In fact, one of the advantages of using OpenTelemetry is the flexibility it provides in choosing and replacing vendor solutions for Observability backend and frontend without any impact to telemetry data generation and collection mechanism.
- Backend: This is where telemetry data is stored and maintained. For most organizations, this data serves as ‘digital evidence’ for their systems and services behavior and so, is quite important from a compliance point of view.
- Frontend: This is where telemetry data is visualized in terms of live dashboards and reports. End-user queries are answered with data analytics, and intelligent insights are derived.
Telemetry Data Usage
To understand a system from outside, an application code must emit signals like logs, traces, and metrics. Each of these signals has a specific significance towards understanding the state of the system.
Logs
A log is a time-stamped message emitted by an application or service, or other components. It’s either structured (preferred) or unstructured with optional metadata.

Unfortunately, logs aren’t extremely useful for tracking code execution, as they typically lack contextual information, such as where they were called from.
Trace (Span)
Unlike logs, a trace represents a unit of work or operation (for example, a business process like Order to Cash or a specific transaction like Checkout for eCommerce systems). It tracks specific operations that a request makes, painting a picture of what happened during the time in which that operation was executed.
Spans are the building blocks of a trace.
![]()
Context propagation is the core concept that enables Distributed Tracing. With context propagation, spans can be correlated with each other and assembled into a trace, regardless of where they were generated.
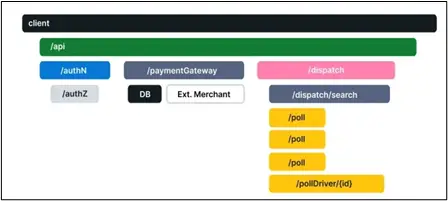
In complex systems, where a user transaction/request would flow through multiple hops (each one in itself being an application or service), distributed trace offers end-to-end visibility and details of what happened at each individual hop.
A trace is made of one or more spans. It means more spans have the same trace ID. The first span represents the root span. Each root span represents a request from start to finish. The spans underneath the parent provide a more in-depth context of what occurs during a request.
Metrics
A metric is a measurement of a resource or service captured during runtime. It is always represented as a pair: the time instance at which the measurement was captured and the value of the measurement itself.
Metrics are an important indicator of Performance and Availability. A trigger event can be raised when the metric value surpasses a certain pre-defined threshold. Metric is particularly important in understanding the behavioral pattern of a resource over a period of time and provides insights into its near-future performance.
