
In our ongoing series of blogs “Unravelling the AI mystery” Digitate continues to explore advances in AI and our experiences in turning AI and GenAI theory into practice. The blogs are intended to enlighten you as well as provide perspective into how Digitate solutions are built.
Please enjoy the blogs
2. Prompt Engineering – Enabling Large Language Models to Communicate With Humans
3. What are Large Language Models? Use Cases & Applications
4. Harnessing the power of word embeddings
written by different members of our top-notch team of data scientists and Digitate solution providers.
What is Prompt Engineering? A Comprehensive Guide
Over the recent years, Generative AI has emerged as a captivating frontier, surpassing conventional AI capabilities. Generative AI, a subset of artificial intelligence, is a technology that powers large machine learning models to create diverse content such as stories, videos, images, music, and even human-like conversations. These ML models use deep neural networks trained on extensive data sets.
While traditional AI excels in making predictions based on existing data, Generative AI takes a bold stride forward by not only predicting but actively generating new data. This transformative technology exhibits a unique blend of creativity and logic, producing diverse forms of data, be it visual or textual. As the spotlight intensifies on Generative AI, specifically Large Language Models (LLMs), a novel field of study is gaining prominence – prompt engineering.
Prompt engineering is a fresh approach in the world of language models, focusing on crafting and refining prompts to optimize the performance of large language models (LLMs). This discipline, deeply rooted in the history of natural language processing (NLP), plays a key role in enhancing LLMs for various tasks, from straightforward ones like answering questions to more complex challenges like arithmetic reasoning. It is not just about creating prompts but involves a range of skills to effectively interact and work with LLMs. Whether you are a researcher aiming to understand these models better or a developer designing prompt techniques, prompt engineering proves crucial. Beyond merely improving the generative AI prompt design through continuous testing and iteration, it enables users to boost safety in LLMs and even introduce new capabilities, such as integrating domain knowledge and external tools.
With the evolution of generative AI and an increasing number of organizations adopting this technology to simplify and streamline their business processes, skilled prompt engineers are now in demand. Prompt engineers are well-versed in NLP techniques and algorithms and can design inputs that help elicit optimal responses from the LLM This enhances the LLM model’s ability to perform its intended tasks better and automate workflows, such as writing emails, generating code, analyzing and creating text, interacting with customers as AI chatbots, composing music, and so on and so forth. While hirings for prompt engineering are likely to boom in the coming years, given organizations’ AI ambitions, these are only expected to supplement the existing talent pool, with existing employees being given training to reskill themselves.
Note: All the examples we show in this blog are generated by OpenAI’s GPT-3.5 model.

What is a prompt?
A prompt is a piece of text or input that instructs a large language model to perform a specific task. Large language models (LLMs) are language-based AI models that are highly adaptable and can be trained to execute and complete tasks like summarizing documents, completing sentences, answering questions, and translating languages. Based on user input, they can generate optimal outputs based on prior training. LLMs are so versatile that they can interact with users endlessly using various input data combinations; it could be inputs given in sentences, phrases, and even single words, and these models can start creating textual content.
As much as Generative AI is capable of creating new content, it cannot do so meaningfully unless some context is shared. LLM requires context to give accurate and desired output. Therefore, this is where prompt engineering helps achieve the desired accuracy with prompts that are well-designed and continually refined.
Why is prompt engineering important?
Prompt engineering instructs LLMs for specific applications so that they can yield more accurate and relevant results in line with user intent. With adaptable scripts and templates, prompt engineers create a prompt library that app developers and professionals working in software engineering and computer science fields can customize to create the required inputs. This helps improve the efficiency of large language models, such as GPT-3 and GPT-4, which have demonstrated a remarkable ability to generate large amounts of human-like text. However, in the absence of sound input data, such models can create responses that could be irrelevant, biased, or even incoherent. Prompt engineering assists in guiding LLMs to generate responses that are accurate and align with the user intent.
Prompt engineering is, thus, instrumental in providing developers with greater control over designing prompts that help improve users’ interactions with LLMs, as well as creating better user experiences with increased flexibility to design prompts for domain-specific applications.
Prompt Elements
Now we know that prompt is the key to getting the best out of LLMs’ capabilities. To achieve this, the prompt should be clear and precise.
For example, if we are interested in understanding prompt engineering from an LLM, you might try something like:
- Explain the concept of prompt engineering. Keep the explanation short, only a few sentences, and don’t be too descriptive.
It’s not clear from the prompt above how many sentences we want or in what style. You might still get some responses, but a better prompt would be the one that is precise. Something like:
- Use 2-3 sentences to explain the concept of prompt engineering to a high school student.
As we cover more examples of prompt engineering and applications, you will notice that a prompt consists broadly of the following elements:
Instruction
A specific task or instruction you want the LLM to perform. For example, an instruction can be to act like a specific persona – “You are a polite librarian.” or “You are a sarcastic chef.”. A task can be something that you want an LLM to perform – “Summarize the book.” or “Give me a recipe.”.
Context
Additional information or background details are provided to guide the LLM in generating more accurate and relevant responses. Including context helps the model better understand the specific circumstances or conditions surrounding a query, enabling it to produce more contextually appropriate answers. This can be particularly useful when dealing with ambiguous or multifaceted questions, as context assists the model in interpreting and responding to the input in a more nuanced and informed manner. The context can be domain-specific information as well.
Input Data
The input or the question that we are interested in the response. For example, for the “summarize the book” instruction, the input can be “‘The Power of Habit’ by Charles Duhigg.”. To give me a recipe, the input can be “An Italian pizza with pineapple.”
Output Indicator
Format for the output. For Example, you can add “Give bullet points for the recipe” in case of a recipe task.
If we combine all the above elements for the recipe task, we get the following prompt:
- You are a sarcastic chef. Give me a recipe for an Italian pizza with pineapple. Give bullet points for the recipe.
The response from LLM is:
Ah, an Italian pizza with pineapple, you rebel! Here’s a recipe that might raise a few eyebrows among pizza purists:
- Dough Drama: Pretend you’re in Naples while making the pizza dough because nothing says authentic like a bit of theater. Throw the flour around for that extra flair.
- Tomato Tango: Use San Marzano tomatoes because if it’s not from Italy, it’s probably not worth your time. Crush them with your bare hands for that primal connection.
- Cheese Choreography: Mozzarella, of course, but do a little dance while you’re sprinkling it on. Maybe even whisper “cheese amore” for good measure.
- Herb Hilarity: Basil is a must, but don’t just place it gently – give it a dramatic flourish like you’re presenting it on a cooking show. Maybe throw in a few oregano twirls for added mystery.
- Olive Oil Opera: Drizzle some extra virgin olive oil, but do it with the passion of an Italian soap opera. Slow and dramatic, as if you’re confessing your love to the pizza.
- Oven Odyssey: Bake it in a wood-fired oven if you have one because authenticity is key. If not, just imagine the wood-fired aroma while it’s in your regular oven.
- Slice Symphony: Cut it into slices with the precision of a ninja. Each slice should tell a story, preferably one with a twist – like pineapple on an Italian pizza.
- Tasting Theater: As you take a bite, channel your inner food critic. Describe the taste as if you’ve discovered the eighth wonder of the culinary world.
Remember, with this pizza, you’re not just cooking – you’re performing a culinary masterpiece. Buon appetito, with a side of sarcasm!
It is not necessary to have all these elements in each prompt. It depends on the task at hand and what elements you want to include in your prompt.
Prompting Techniques
At this stage, it’s clear that making prompts better makes a big difference in getting good results for various tasks. That’s what prompt engineering is all about. While the simple examples were enjoyable, in this part, we dive into fancier prompt engineering tricks that help us do cooler and more interesting things. These are called prompting techniques. We will cover a few of the most used prompting techniques here.
Zero-shot prompting
Nowadays, LLMs are tuned to understand and carry out instructions. They learn from tons of information, making them able to do certain tasks without specific training, i.e., they are capable of performing these tasks as “zero-shot.” For example,
- Prompt:
- Classify the text into neutral, negative, or positive.
- Text: I think the vacation is okay.
- Sentiment:
- Output:
- Neutral
Few-shot prompting
Even though LLMs are pretty good at zero-shot, they struggle with tougher and more complex tasks in that setting. To help them get better, we use something called few-shot prompting. This means we show examples in the prompt to guide the model to do a better job. These examples act like training wheels for the model to respond better in similar situations later.
- Prompt:
- A “whatpu” is a small, furry animal native to Tanzania. An example of a sentence that uses the word whatpu is:
- We were traveling in Africa, and we saw this very cute whatpus.
- To do a “farduddle” means to jump up and down fast. An example of a sentence that uses the word farduddle is:
- Model’s output:
- When we won the game, we all started to farduddle in celebration.
If we give the model just one example (like a 1-shot), we can see it learns how to do the task. But for harder stuff, we can try giving it more examples (like 3-shot, 5-shot, 10-shot, and so on) to see if that helps.
Chain-of-Thought (CoT) prompting:
Chain-of-thought prompting enables LLM to do better on more complex tasks that require reasoning. CoT enables LLM to add intermediate reasoning steps, which helps the model reach the correct output. For example,
- Prompt:.
- I went to the market and bought 10 apples. I gave 2 apples to the neighbor and 2 to the repairman. I then went and bought 5 more apples and ate 1. How many apples did I remain with?
- Output:
- 11 apples
The answer is incorrect! Now, let’s try with the CoT prompt.
- Prompt:
- I went to the market and bought 10 apples. I gave 2 apples to the neighbor and 2 to the repairman. I then went and bought 5 more apples and ate 1. How many apples did I remain with?
- Let’s think step by step.
- Output:
- First, you started with 10 apples.
- You gave away 2 apples to the neighbor and 2 to the repairman, so you had 6 apples left.
- Then you bought 5 more apples, so now you had 11 apples.
- Finally, you ate 1 apple so that you would remain with 10 apples.
Just by adding “Let’s think step by step,” LLM was able to think through the problem and give the correct response.
RAG prompting
General-purpose language models can undergo fine-tuning to excel in various common tasks like sentiment analysis and named entity recognition, which typically don’t demand additional background knowledge.
- For more intricate and knowledge-intensive assignments, a language model-based system can be developed to tap into external knowledge sources. This approach enhances factual consistency, boosts the reliability of generated responses, and helps counteract the issue of “hallucination.”
- Meta AI researchers have introduced an approach known as Retrieval Augmented Generation (RAG) to tackle such knowledge-intensive tasks. RAG combines an information retrieval component with a text generator model. The beauty of RAG lies in its ability to be fine-tuned and have its internal knowledge modified efficiently, all without requiring a complete retraining of the entire model.
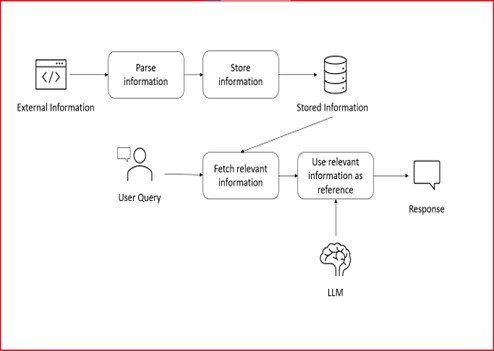
- In the RAG framework, the input triggers a retrieval process that fetches a set of pertinent/supporting documents from a specified source, such as Wikipedia. These documents are then concatenated as context with the original input prompt and are fed into the text generator, ultimately producing the final output. This adaptability of RAG proves valuable in scenarios where facts may evolve over time, a critical advantage as the parametric knowledge of large language models remains static. RAG empowers language models to sidestep the need for retraining, facilitating access to the latest information for generating reliable outputs through retrieval-based generation.
- The RAG framework with LLMs would have a flow like the diagram below:
Applications
Data Generation
Data is the key to all data science tasks. And more often, data is not available to start with, or the available data is not enough to solve the problem. Creativity and a general understanding of LLMs can be used to generate data. For example,
Generate examples of emails and classify them as spam and not spam. Follow the following format:
- Email:
- Classification:
Chat-based Search Engine
To have a search engine that is like a chatbot. Cool, isn’t it? This is what Bing & Google search have now become. In fact, all the conversations are backed by searched results, so you get the factually correct results.
Coding Assistant
LLMs are proving to be good at code generation tasks. If we can carefully frame the prompt and convey the requirement, the results are surprising. It can also assist you with debugging the code.
Creative Writing
LLMs are highly creative and can produce poems and prose. They can mimic the work of some renowned artists so well that it becomes difficult to distinguish it from their original work.
Risks
While using a piece of technology as amazing and powerful as LLMs and prompt engineering, it becomes imperative to think about the risks involved if not used in the right way. It is important to think about its misuse and what the safety practices could be to avoid them. Let’s look at some of them below.
Adversarial Prompting
- Adversarial prompting means using prompts that might lead to unethical acts and responses from the LLM. It might lead the LLM to reveal some data that is not intended for everybody to see. It is crucial as it can give us a direct understanding of possible risks and misuse. Diving deeper can also help us identify how these risks can be tackled.
- Some of the ways in which an adversarial attack is possible:
- Trying to override previous instructions and modify the intended output.
- Trying to trick the LLM into revealing the prompt used to set the context. It is dangerous because it’s possible that for setting the context some confidential information was used.
- Trying to make it generate responses that are not socially acceptable and even illegal sometimes.
- However, the good news is that most researchers and developers creating LLMs are now aware of the design flaws that allow such attacks. So, if you are not using a very sophisticated and clever prompt, it’s not going to be easy to make such an attack.
Factual Correctness
- As we know, most LLMs have a cut-off date for the data on which they have been trained and cannot correctly respond to the factual questions that are related to any day after that date. Or any information that was not a part of the training data. But even for such questions, LLMs tend to come up with a response that is not correct, meaning they hallucinate.
- Ways to mitigate this include adding a phrase like:
- If you do not know, say, “I don’t know.”
- Another approach that we have already discussed in this blog is RAG prompting. This allows the LLM to tap into external knowledge sources and enhance factual consistency.
- Hallucinations are prominent in code-generation applications as well. There will be a requirement for humans in the loop to verify the generated code.
