
Over the recent years, Generative AI has emerged as a captivating frontier, surpassing conventional AI capabilities. While traditional AI excelled in making predictions based on existing data, Generative AI takes a bold stride forward by not only predicting but actively generating new data. This transformative technology exhibits a unique blend of creativity and logic, producing diverse forms of data, be it visual or textual. As the spotlight intensifies on Generative AI, specifically Large Language Models (LLMs), a novel field of study is gaining prominence — prompt engineering.
Prompt engineering is a fresh approach in the world of language models, focusing on crafting and refining prompts to make the most out of large language models (LLMs). This discipline plays a key role in enhancing LLMs for various tasks, from straightforward ones like answering questions to more complex challenges like arithmetic reasoning. It’s not just about creating prompts but involves a range of skills to effectively interact and work with LLMs. Whether you’re a researcher aiming to understand these models better or a developer designing prompt techniques, prompt engineering proves crucial. Beyond merely improving prompt design, it enables users to boost safety in LLMs and even introduce new capabilities, such as integrating domain knowledge and external tools.
Note: All the examples we show in this blog are generated by OpenAI’s GPT-3.5 model.
Prompt Elements
Now we know that prompt is the key to get the best of LLMs’ capabilities. To achieve this, the prompt should be clear and precise. Let’s take an example to understand the difference between a prompt and a better prompt.
Suppose, if we are interested in understanding prompt engineering from an LLM. We might try something like:

Pretty intuitive, but there is still room for assumptions because it’s not clear from the prompt above how many sentences we want or in what style. We might still get some responses, but a better prompt would be the one which is precise. Something like:
![]()
Now that we have clearly defined our requirement, there is not so much room for assumptions, and we will get a response which is tailored to our need.
As we cover more examples of prompt engineering and applications, you will notice that a prompt consists broadly of the following four elements:
1. Instruction:
This is the main directive given to the model. A specific instruction or task you want the LLM to perform. For example, an instruction can be to act like a specific persona — “You are a polite librarian.” or “You are a sarcastic chef.”. A task can be something that you want an LLM to perform — “Summarize the book.” or “Give me a recipe.”.
2. Context:
Additional information or background details provided to guide the LLM in generating more accurate and relevant responses. Including context helps the model better understand the specific circumstances or conditions surrounding a query, enabling it to produce more contextually appropriate answers. This can be particularly useful when dealing with ambiguous or multifaceted questions, as context assists the model in interpreting and responding to the input in a more nuanced and informed manner. The context can be domain specific information as well.
3. Input Data:
Input data can be understood as the input or question for which we are interested in a response. For example, for “Summarize the book” instruction, the input data can be “‘The Power of Habit’ by Charles Duhigg.”. For “Give me a recipe”, the input data can be “An Italian pizza with pineapple.”.
4. Output Indicator:
It comes in handy when we want to specify the format for the output. For Example, you can add “Give bullet points for the recipe” in case of recipe task.
If we combine all the above elements for the recipe task, we get the following prompt:

The response from LLM is:
It is not necessary to have all these elements in each prompt. It depends on the task at hand what elements you want to include in your prompt. Even in the above example, there is no added context.
Prompting Techniques
At this stage, it’s clear that making prompts better makes a big difference in getting good results for various tasks. That’s what prompt engineering is all about. While the simple examples were enjoyable, in this part, we dive into fancier prompt engineering tricks that help us do cooler and more interesting things. These are called prompting techniques. We will cover a few of the most used prompting techniques here.
Zero-shot prompting:
LLMs nowadays are tuned to understand and carry out instructions. They learn from tons of information, making them able to do certain tasks without specific training, i.e., they are capable of performing these tasks as “zero-shot”. You just have to specify the instruction and input data. For example,
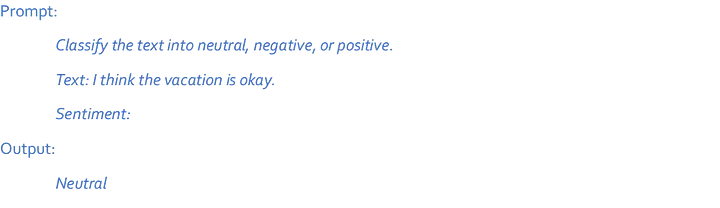
Few-shot prompting:
Even though LLMs are pretty good at zero-shot, they struggle with tougher and complex tasks in that setting. To help them get better, we use something called few-shot prompting. This means we show examples in the prompt to guide the model to do a better job. These examples act like training wheels for the model to respond better in similar situations later.

As you can see, if we give the model just one example (like a 1-shot), we can see that it learns how to do the task. But for harder stuff, we can try giving it more examples (like 3-shot, 5-shot, 10-shot, and so on) to see if that helps.
Chain-of-Thought (CoT) prompting:
Chain-of-Thought prompting enables LLM to do better on more complex tasks that require reasoning. CoT enables LLM to add intermediate reasoning steps which helps the model reach the correct output. For example,

The answer is incorrect! Now let’s try with the CoT prompt.

Just by adding “Let’s think step by step”, LLM was able to think through the problem and give the correct response.
RAG prompting:
General-purpose language models can undergo fine-tuning to excel in various common tasks like sentiment analysis and named entity recognition, tasks that typically don’t demand additional background knowledge.
For more intricate and knowledge-intensive assignments, a language model-based system can be developed to tap into external knowledge sources. This approach enhances factual consistency, boosts the reliability of generated responses, and helps counteract the issue of “hallucination”.
Meta AI researchers have introduced an approach known as Retrieval Augmented Generation (RAG) to tackle such knowledge-intensive tasks. RAG combines an information retrieval component with a text generator model. The beauty of RAG lies in its ability to be fine-tuned and have its internal knowledge modified efficiently, all without requiring a complete retraining of the entire model.
In the RAG framework, the input triggers a retrieval process that fetches a set of pertinent/supporting documents from a specified source, such as Wikipedia. These documents are then concatenated as context with the original input prompt and are fed into the text generator, ultimately producing the final output. This adaptability of RAG proves valuable in scenarios where facts may evolve over time, a critical advantage as the parametric knowledge of large language models remains static. RAG empowers language models to sidestep the need for retraining, facilitating access to the latest information for generating reliable outputs through retrieval-based generation.
We can apply the same concept to LLMs as well. LLMs are trained on a huge amount of data which typically has a cut-off date and does not include private data. This prevents LLM to perform some tasks based on some specific data, which is not part of training data. By adding specific information or domain information in the prompt as a context, LLMs can answer the queries factually and accurately.
The RAG framework with LLMs would have a flow as shown in the below diagram:

Applications
Data Generation
Data is the key to all data science tasks. And more often data is not available to start with, or the available data is not enough to solve the problem. Creativity and general understanding of LLMs can be used to generate data. For example,

Chat based Search Engine
To have a search engine which is like a chatbot. Cool, isn’t it? This is what Bing & Google search have now become. In fact, all the conversations are backed by searched results, so you get the factually correct results. This is one of the uses of RAG.
Coding Assistant
LLMs are proving to be good at code generation tasks. If we can carefully frame prompt and convey the requirement, results are surprisingly good. Not only generation of code, but it can also assist you with debugging, refactoring, documenting, or optimizing the code. LLMs can even translate code written in one programming language to another.
Creative Writing
LLMs are highly creative and can produce various forms of content like poems, prose, emails, blogs, Instagram post captions, etc. They can also mimic the work of some renowned artists so well that it becomes difficult to distinguish it from their original work. There are many products available in the market which assist humans in content creation by leveraging the power of LLMs.
Risks
While using a piece of technology as amazing and powerful as LLMs, it becomes imperative to think about the risks involved if prompt engineering is not used in the right way. It is important to think about its misuse and what could be the safety practices to avoid them. Let’s look at some of them below.
Adversarial Prompting:
Adversarial prompting means using prompts which might lead to unethical and unintended acts and responses from the LLM. Adversarial prompting is crucial as it can also give us a direct understanding of the involved risks and possible misuses. This can help us tackle these issues.
Some of the ways in which adversarial prompting is possible:
· Trying to override previous instructions and modify the intended output.
· Trying to trick the LLM to reveal the prompt used to set the context. It is dangerous because it’s possible that for setting the context, some confidential information was used.
· Trying to make it generate responses which are not socially acceptable, or politically incorrect.
However, the good news is that most of the researchers and developers are aware of the design flaws which allow such attacks. Therefore, more robust LLMs are being developed. So, if you are not using a very sophisticated and clever prompt, it’s not going to be easy to make such an attack.
Factual Correctness:
LLMs are trained in a way that they always try to respond to queries even if they do not have information around them. This could be because it was not a part of the training data, or they do not remember the information. Either way, the response can be something non-existent. In other words, they hallucinate. Hallucinations are quite prominent in most of the current LLMs.
One of the ways to reduce hallucination include adding a phrase to the prompt as provided below:
![]()
Another approach that we have already discussed in this blog is RAG prompting. This allows the LLM to tap into external knowledge sources and enhance factual consistency and accuracy.
Closing notes
With the wider penetration of Generative AI solutions, the field of prompt engineering is witnessing tremendous growth. As these AI models are emerging with unprecedented levels of intelligence, prompt engineering is offering a very powerful vehicle to interact with these sophisticated AI models. A carefully crafted prompt holds the key to unlock the true potential of Generative AI models.
