
The past couple of years have been a great time to be an I&O leader responsible for IT infrastructure, applications and cloud operations. The tools available to manage IT performance and stability are aplenty. It is widely believed that most enterprises have more than 12-15 IT (information technology) operations tools and IT operations engineers use metrics, events, logs and traces from these tools to detect anomalies and resolve issues in digital business apps. This is often along with a great deal of tacit knowledge from L2/L3 engineers and architects. Modern day hybrid cloud distributed architectures introduce a bevy of operational challenges around managing system availability and performance. However, these large number of tools are not exactly helping overcome these new set of challenges. When applied to complex, dynamic and volatile distributed architectures of current day IT estates, these tools generate a massive volume of data (often in TBs of logs and billions of events per week) with limited abilities to visualize and leverage it. This makes IT service sluggish and unresponsive while being expensive in the face of this massive surge of data. AIOps is being viewed by many enterprises as an approach and construct to make operations agile, responsive and proactive in the face of modern-day complexities. AIOps helps understand the massive volumes of operational data and extract actionable insights in real time. However, enterprises are still figuring out how to weave AIOps capabilities into the enterprise “Run” tools architecture. They are not helped by confusing and inconsistent point of views from pundits and varying degrees of marketing from vendors. I&O leaders are caught in a never-ending cycle of architecting their tools landscape to anticipate and address new technology innovations. Their tools landscape typically consists of:
- Monitoring Tools (Server, Storage, NW, APM, BPM, DEM, Log, amongst others)
- Event Management tools
- ITSM
- Notification and Collaboration Solutions
- Orchestration and Automation Tools
- Visualization tools at multiple layers
The most common approach is to develop a pipeline of capabilities using these tools to move work by engineers, as represented in the following figure – essentially organized as a pipeline to hand over data (metric, event, log) to the next tool and take actions predominantly based on rules.
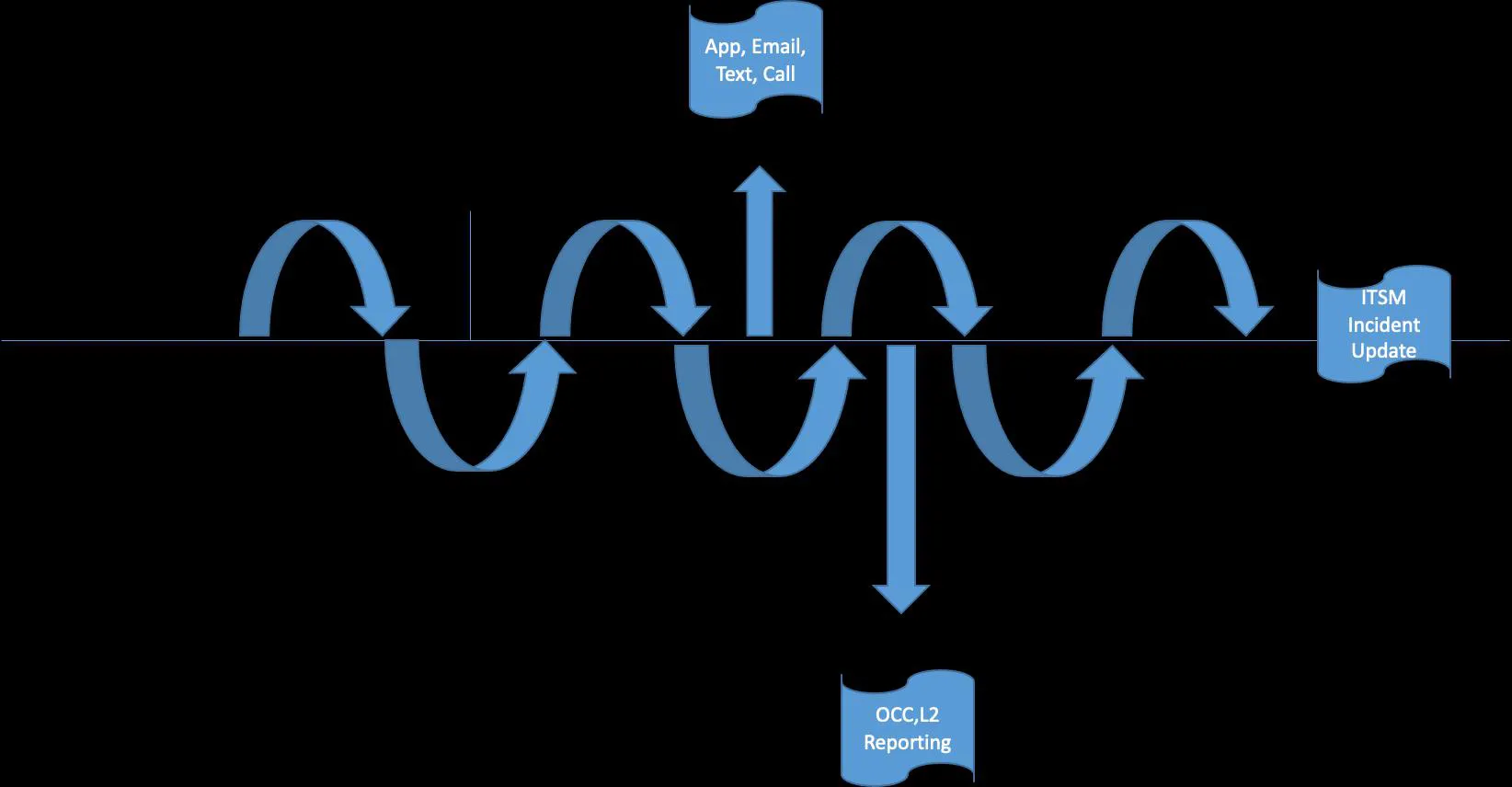
- Not only there are integration challenges with this model – tool integration is often done by third party approaches, but there are also always a considerable number of exceptions that add complexity to the architecture based on target systems, infrastructure teams and processes.
- Given the pressure of modernizing the toolset – the most common response of I&O teams is to rip and replace the traditional event management tool with an AI/ML based tools for alert correlation/suppression/aggregation. This does not provide future proofing credibility to this architecture.
- This approach has multiple points of failures – it does not abstract the tacit knowledge, fails to create a singular context of the enterprise and allows greater risk due to multiple couplings.
- Lack of unified data foundation – this does not align well with the DevOps frameworks and SRE teams as a common standard and model is not available for developers and engineers to work with.
A platform-oriented approach is the recommended and better alternative. This approach consolidates all the monitoring solutions to deposit metrics, events, logs and traces to a performance data lake which then becomes the unified center data foundation for a platform with context, analytics, automation and notification capabilities as illustrated in the following figure.
The key advantages of this approach are:
- Flexibility: Allows federated approach for monitoring components and a centralized approach to context, analytics and automation
- As organizations build in better observability – this architecture becomes increasingly effective in exploiting the approach without making any changes.
- Allows enough abstraction to enforce a standard model driven approach for SRE teams.
- Eliminates the need for large number of scripts, policies and their maintenance.
- Creates the foundation for autonomous enterprise operations.
- Handles complexity, scale and diversity of target environment by blending legacy, API and data base and problem-solving approaches in the architecture.
I&O organizations are advised to develop tools architecture in the platform-oriented model that exploits technology advancements in using AI/ML for operations at all layers, the new observability stacks, immersive engagement and collaboration. This will position the operations teams to be more agile, resilient, build stronger monitoring data model in applications and impact business outcomes. The platform-oriented tools architecture enables operations to mature across various levels of maturity from Reactive to Automated to Intelligent through to Autonomous. Moving through each of these maturity levels, enables a continuously reducing human involvement, greater abstraction of context and leveraging intelligence for self-driving resolution of augmented problems. This tools architecture approach also allows enterprises to scale to higher volumes without impacting operations management. It places enterprises in a better position to make informed and well-reasoned build versus buying decisions for their business needs
